For a project I’m parsing a textual representation of a time duration. I stumbled on an interesting regex problem while doing that.
Concretely, I’m parsing these indications on my Audible library page of how long I’ve listened to an audiobook. I want to extract the hours and/or minutes from this duration.
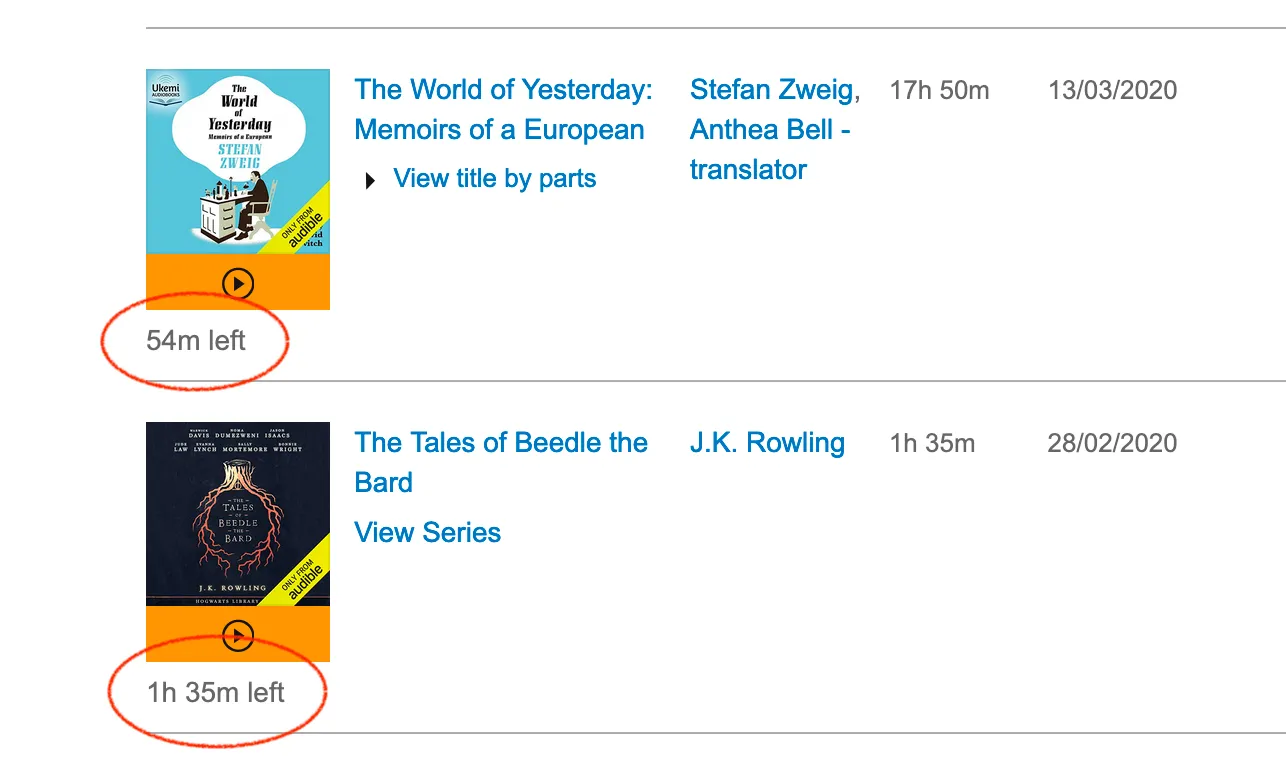
This was my first regex attempt : /(\d{1,2})h(?:\s?(\d{1,2})m)?/
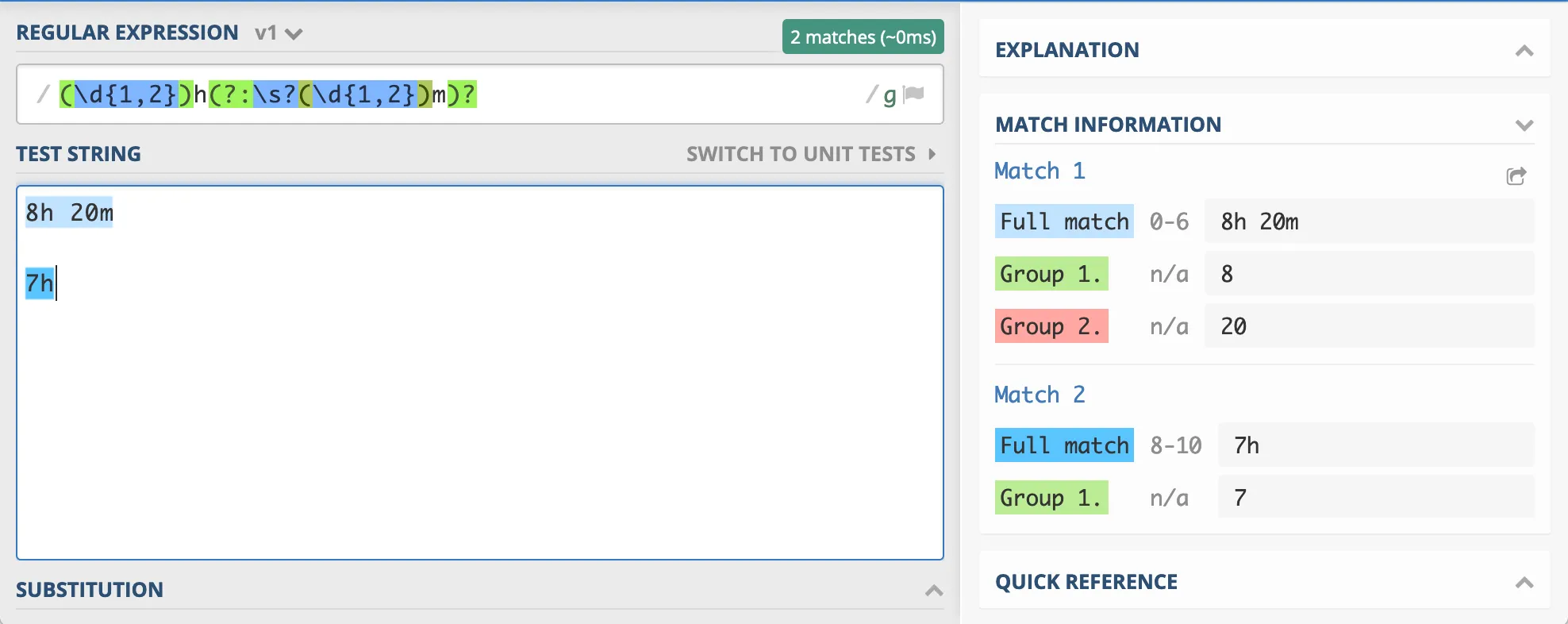
It seemed to work well. But as the regex nerd might see, I soon encountered a bug when there was less than one hour left: the hours had disappeared, and my regex didn’t account for that.
So how to solve this issue?
A first idea is to make the hour part and minute part optional with the ? operator:
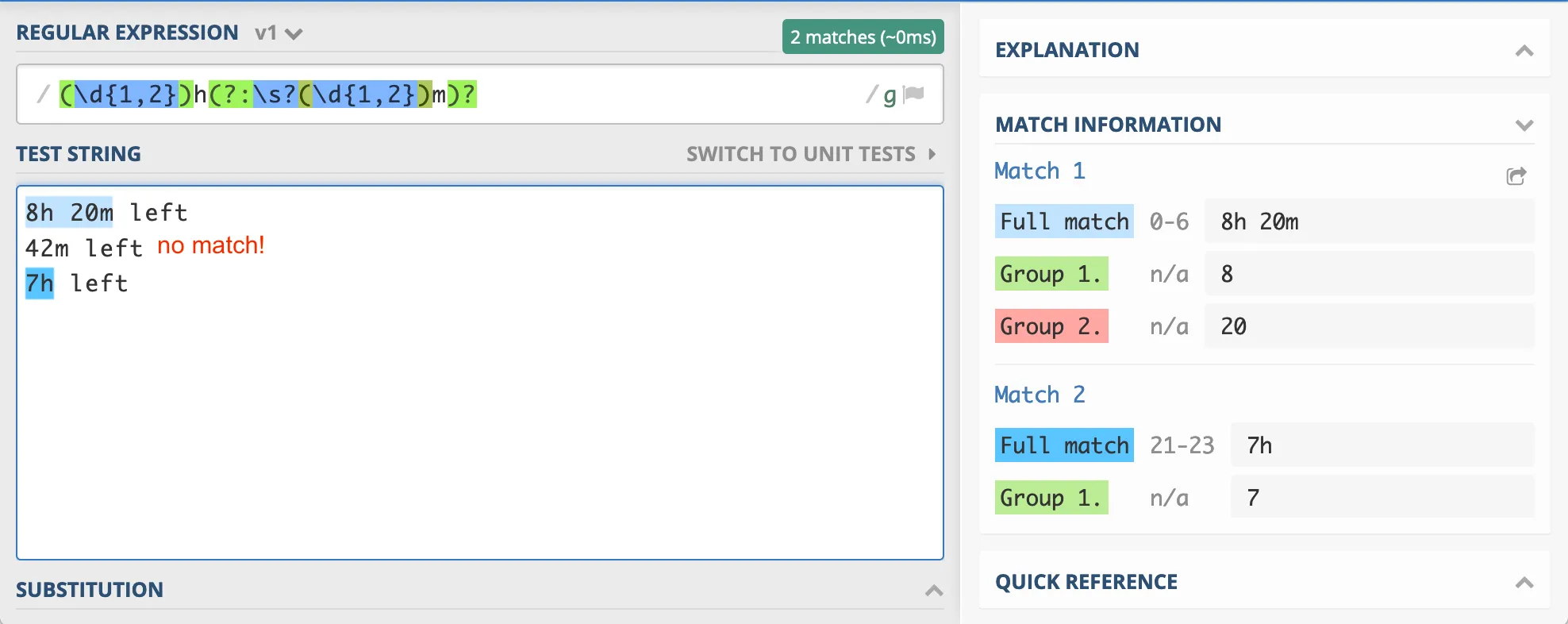
/(?:(\d{1,2})\sh)?\s(?:\s?(\d{1,2})\s*m)?/
This seems to work. And it does, given that the input string is always exactly in the format “8h 2m left”.
But one “issue”: this regex isn’t robust in the input it accepts.
If any characters are added before or behind, it will fail. Because it also matches the empty string!
See this test, note the space in front of the 8m.
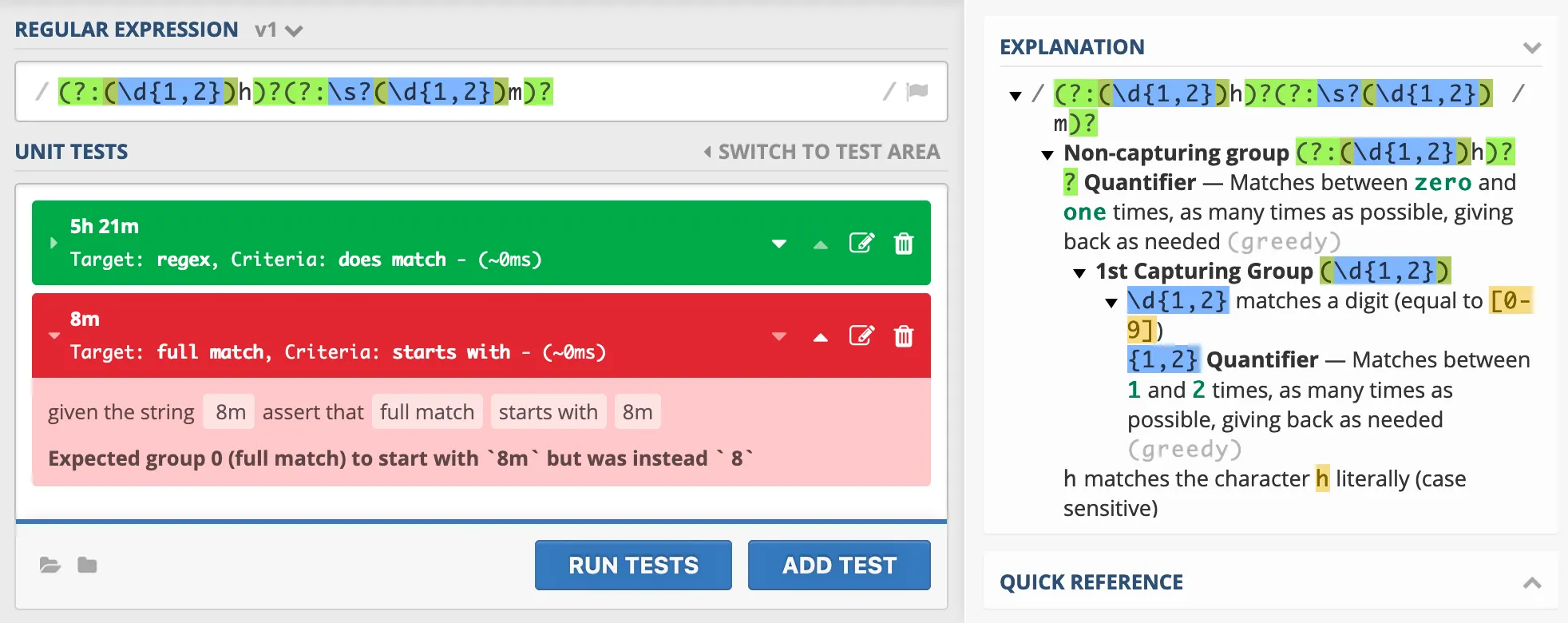
Why? Because the regex a?b? matches either a or b, but matching nothing is also OK! And for the quick thinkers: a|b would in this case not be a solution, because there are capturing groups in a and b.
I’m abstracting a as the hour-matcher and b as the minute matcher here.
That’s the problem that intrigued me:
How can you match ‘a’, ‘b’, or ‘a and b’ while preserving the same single capturing groups in a and b?
I took this as a regex puzzle and came up with some solutions:
Solution 1: Brute force with code
The first solution is not really a regex solution: use a global flag on the previous regex, and then to write code to scan for “valid” matches. Empty string matches are discarded, only a filled match is kept.
Works, but I’m looking for a regex-only solution.
Solution 2: Brute force regex
A straightforward regex solution is this: a|b|ab
But I didn’t like this. Because I have a capturing group in both a and b, and by duplicating a and b into ab, that means I’d also duplicate the capturing groups.
Then we go from this simple scenario:
- match group 1 contains hours
- match group 2 contains minutes
To this more complicated one:
- match group 1 contains hours if the string is an hour-only string like ‘8h left’
- match group 2 contains minutes if the string is a minute-only string like ‘8h left’
- match group 3 contains hours if the string is combined hour-minute string like ‘8h 3m left’
- match group 4 contains minutes if the string is combined hour-minute string like ‘8h 3m left’
That means the code handling the regex match would need if/else logic to deal with these scenarios. A compromise you might take, but I’m looking for a “regex-only” solution.
Solution 3: Explicitly not matching an empty string?
We could solve this if we could tell the regex that it can never match an empty string somehow.
I tried to look around for this briefly, but couldn’t find anything that worked.
See this StackOverflow thread and let me know if you make it work :)
Solution 4: Only match when something good lies ahead
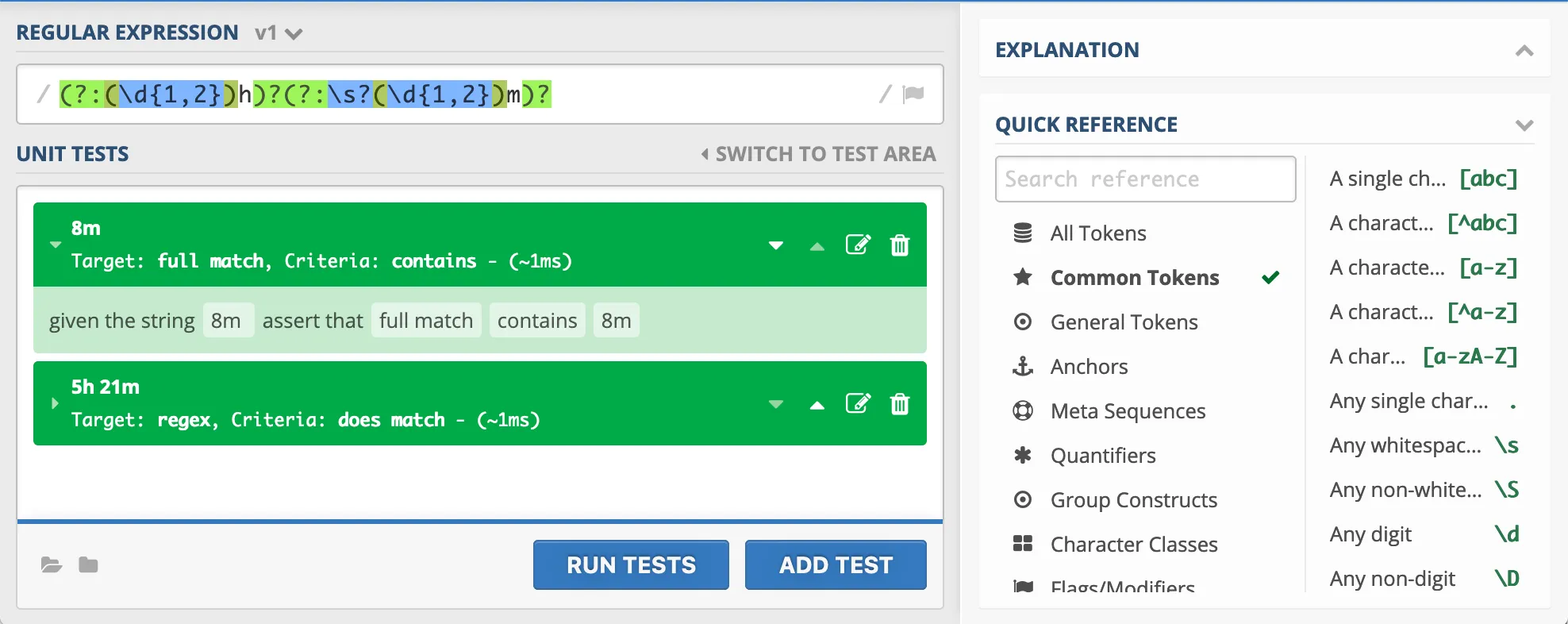
This is the solution that finally worked for me: a positive lookahead.
This piece of regex (?=\d{1,2}\s*(?:h|m)) in front of the rest tells the matcher that it should look ahead for something with one or two digits and a ‘h’ or ‘m’. Only when it finds this in front of itself, it can start with the real matching and capturing groups.
It can be abstracted as (?=a|b)a?b?, but my concrete implementation takes some shortcuts there.
This solution has the robustness against spaces and only 2 capturing groups. I added the global flag in this example to demonstrate what it does:
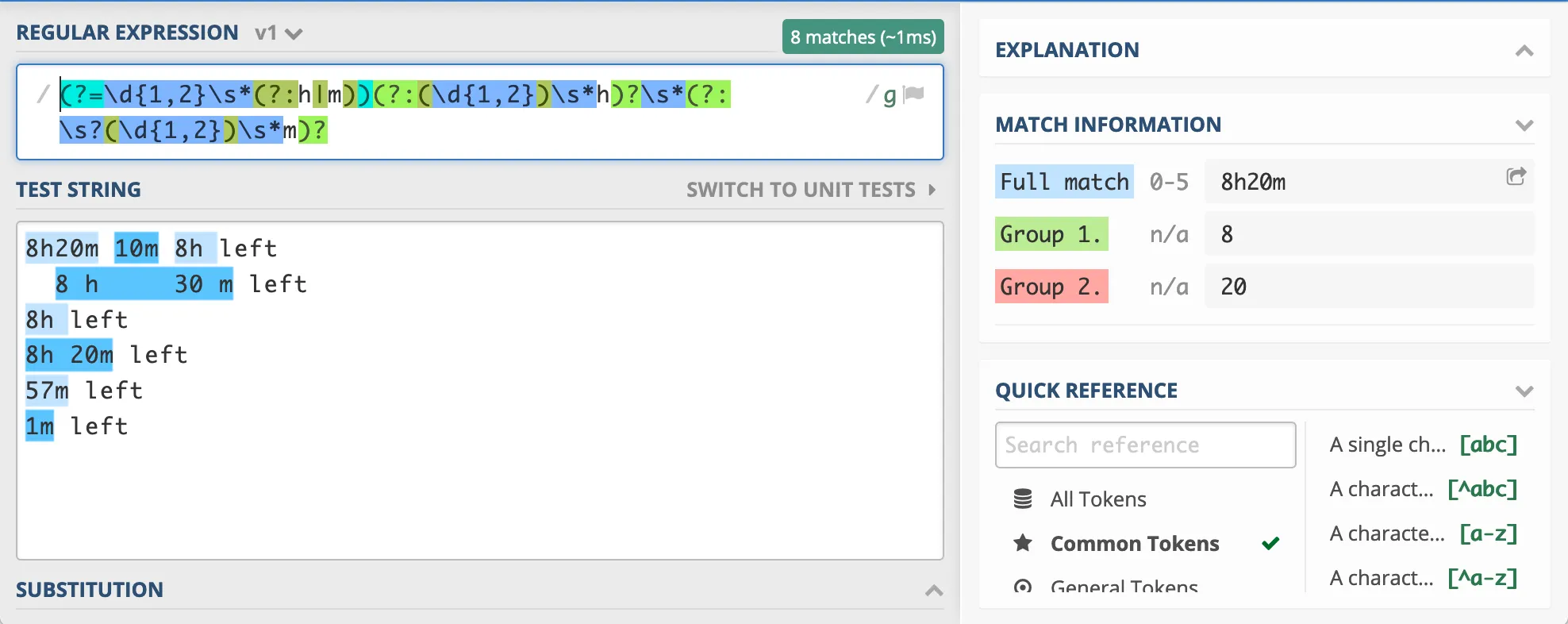
See this regex101 for the full regex.
The regex does not support the notion of “days” or “seconds”, or epxressions like “less than one minute”. I hope these will not appear in the Audible page :)